What Is A Robots.txt File? And How Do You Create One? (Beginner’s Guide) by TechMafia

Did you know that you have complete control over who crawls and indexes your site, down to individual pages?
The way this is done is through a file called Robots.txt.
Robots.txt is a simple text file that sites in the root directory of your site. It tells “robots” (such as search engine spiders) which pages to crawl on your site, which pages to ignore.
While not essential, the Robots.txt file gives you a lot of control over how Google and other search engines see your site.
When used right, this can improve crawling and even impact SEO.
But how exactly do you create an effective Robots.txt file? Once created, how do you use it? And what mistakes should you avoid while using it?
In this post, I’ll share everything you need to know about the Robots.txt file and how to use it on your blog.
Let’s dive in:
What is a Robots.txt file?
Back in the early days of the internet, programmers and engineers created ‘robots’ or ‘spiders’ to crawl and index pages on the web. These robots are also known as ‘user-agents.’
Sometimes, these robots would make their way onto pages that site owners didn’t want to get indexed. For example, an under construction site or private website.
To solve this problem, Martijn Koster, a Dutch engineer who created the world’s first search engine (Aliweb), proposed a set of standards every robot would have to adhere to. These standards were first proposed in February 1994.
On 30 June 1994, a number of robot authors and early web pioneers reached consensus on the standards.
These standards were adopted as the “Robots Exclusion Protocol” (REP).
The Robots.txt file is an implementation of this protocol.
The REP defines a set of rules every legitimate crawler or spider has to follow. If the Robots.txt instructs robots to not index a web page, every legitimate robot – from Googlebot to the MSNbot – has to follow the instructions.
Note: A list of legitimate crawlers can be found here.
Keep in mind that some rogue robots – malware, spyware, email harvesters, etc. – might not follow these protocols. This is why you might see bot traffic on pages you’ve blocked via Robots.txt.
There are also robots that don’t follow REP standards that aren’t used for anything questionable.
You can see any website’s robots.txt by going to this url:
http://[website_domain]/robots.txt
For example, here is Facebook’s Robots.txt file:
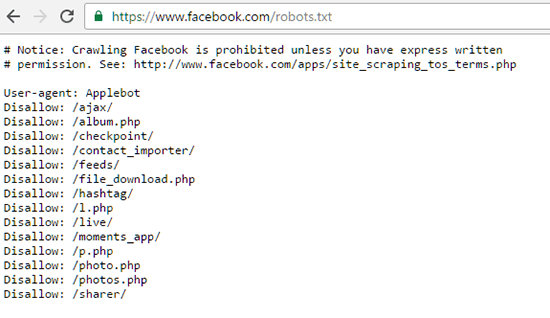
And here is Google’s Robots.txt file:
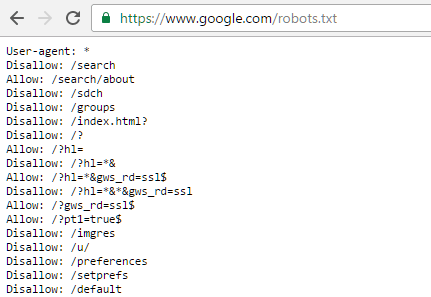
Use of Robots.txt
Robots.txt is not an essential document for a website. Your site can rank and grow perfectly well without this file.
However, using the Robots.txt does offer some benefits:
- Discourage bots from crawling private folders – Although not perfect, disallowing bots from crawling private folders will make them much harder to index – at least by legitimate bots (such as search engine spiders).
- Control resource usage – Every time a bot crawls your site, it drains your bandwidth and server resources – resources that would be better spent on real visitors. For sites with a lot of content, this can escalate costs and give real visitors a poor experience. You can use Robots.txt to block access to scripts, unimportant images, etc. to conserve resources.
- Prioritize important pages – You want search engine spiders to crawl the important pages on your site (like content pages), not waste resources digging through useless pages (such as results from search queries). By blocking off such useless pages, you can prioritize which pages bots focus on.
How to find your Robots.txt file
As the name suggests, Robots.txt is a simple text file.
This file is stored in the root directory of your website. To find it, simply open your FTP tool and navigate to your website directory under public_html.

This is a tiny text file – mine is just over 100 bytes.
To open it, use any text editor, such as Notepad. You may see something like this:
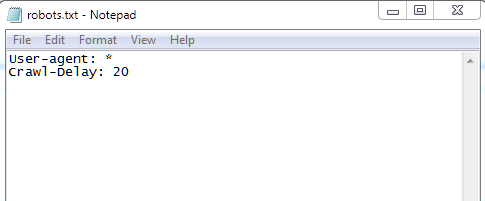
There is a chance you won’t see any Robots.txt file in your site’s root directory. In this case, you’ll have to create a Robots.txt file yourself.
Here’s how:
How to create a Robot.txt file
Since Robots.txt is a basic text file, creating it is VERY simple – just open a text editor and save an empty file as robots.txt.
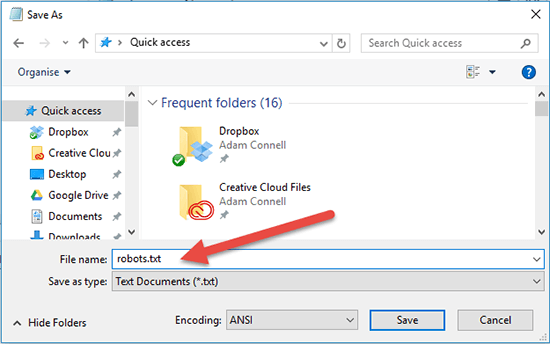
To upload this file to your server, use your favorite FTP tool (I recommend using WinSCP) to log into your web server. Then open the public_html folder and open your site’s root directory.
Depending on how your web host is configured, your site’s root directory may be directly within the public_html folder. Or, it might be a folder within that.
Once you’ve got your site’s root directory open, just drag & drop the Robots.txt file into it.
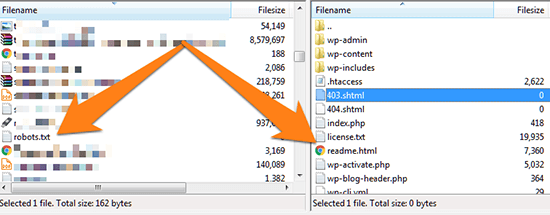
Alternatively, you can create the Robots.txt file directly from your FTP editor.
To do this, open your site root directory and Right Click -> Create new file.
In the dialog box, type in “robots.txt” (without quotes) and hit OK.
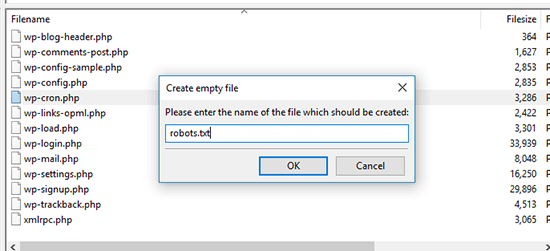
You should see a new robots.txt file inside:

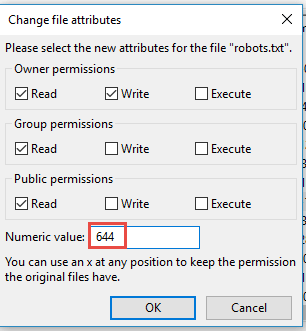
Lastly, make sure that you’ve set the right file permission for the Robots.txt file. You want the owner – yourself – to read and write the file, but not to others or the public.
Your Robots.txt file should show “0644” as the permission code.
If it doesn’t, right click your Robots.txt file and select “File permissions…”
There you have it – a fully functional Robots.txt file!
But what can you actually do with this file?
Next up, I’ll show you some common instructions you can use to control access to your site.
How to use Robots.txt
Remember that Robots.txt essentially controls how robots interact with your site.
Want to block search engines from accessing your entire site? Simply change permissions in Robots.txt.
Want to block Bing from indexing your contact page? You can do that too.
By itself, the Robots.txt file won’t improve your SEO, but you can use it to control crawler behaviour on your site.
To add or modify the file, simply open it in your FTP editor and add the text directly. Once you save the file, the changes will be reflected immediately.
Here are some commands you can use in your Robots.txt file:
1. Block all bots from your site
Want to block all robots from crawling your site?
Add this code to your Robots.txt file:
User-agent: *
Disallow: /
This is what it would look like in the actual file:
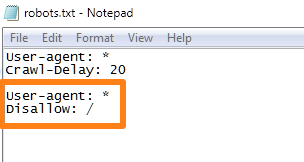
To put it simply, this command tells every user agent (*) to not access any files or folders on your site.
Here’s the complete explanation of exactly what’s happening here:
- User-agent:* – The asterisk (*) is a ‘wild-card’ character that applies to every object (such as file name or in this case, bot). If you search for “*.txt” on your computer, it will show up every file with the .txt extension. Here, the asterisk means that your command applies to every user-agent.
- Disallow: / – “Disallow” is a robots.txt command prohibiting a bot from crawling a folder. The single forward slash (/) means that you’re applying this command to the root directory.
Note: This is ideal if you run any kind of private website such as a membership site. But be aware that this will stop all legitimate bots such as Google from crawling your site. Use with caution.
2. Block all bots from accessing a specific folder
What if you want to prevent bots from crawling and indexing a specific folder?
For example, the /images folder?
Use this command:
User-agent: *
Disallow: /[folder_name]/
If you wanted to stop bots from access the /images folder, here’s what the command would look like:
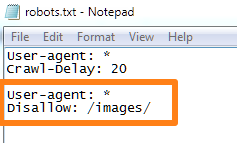
This command is useful if you have a resource folder that you don’t want to overwhelm with robot crawler requests. This can be a folder with unimportant scripts, outdated images, etc.
Note: The /images folder is purely an example. I’m not saying you should block bots from crawling that folder. It depends on what you’re trying to achieve.
Search engines typically frown on webmasters blocking their bots from crawling non-image folders, so be careful when you use this command. I’ve listed some alternatives to Robots.txt for stopping search engines from indexing specific pages below.
3. Block specific bots from your site
What if you want to block a specific robot – such as Googlebot – from accessing your site?
Here’s the command for it:
User-agent: [robot name]
Disallow: /
For example, if you wanted to block Googlebot from your site, this is what you’d use:
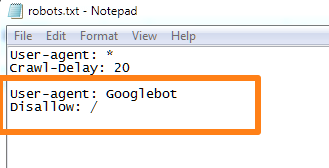
Each legitimate bot or user-agent has a specific name. Google’s spider, for instance, is simply called “Googlebot”. Microsoft runs both “msnbot” and “bingbot”. Yahoo’s bot is called “Yahoo! Slurp”.
To find exact names of different user-agents (such as Googlebot, bingbot, etc.) use this page.
Note: The above command would block a specific bot from your entire site. Googlebot is purely used as an example. In most cases you would never want to stop Google from crawling your website. One specific use case for blocking specific bots is to keep the bots that benefit you coming to your site, while stopping those that don’t benefit your site.
4. Block a specific file from being crawled
The Robots Exclusion Protocol gives you fine control over which files and folder you want to block robot access to.
Here’s the command you can use to stop a file from being crawled by any robot:
User-agent: *
Disallow: /[folder_name]/[file_name.extension]
So, if you wanted to block a file named “img_0001.png” from the “images” folder, you’d use this command:
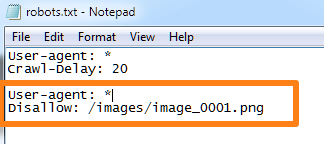
5. Block access to a folder but allow a file to be indexed
The “Disallow” command blocks bots from accessing a folder or a file.
The “Allow” command does the opposite.
The “Allow” command supersedes the “Disallow” command if the former targets an individual file.
This means that you can block access to a folder but allow user-agents to still access an individual file within the folder.
Here’s the format to use:
User-agent: *
Disallow: /[folder_name]/
Allow: /[folder_name]/[file_name.extension]/
For example, if you wanted to block Google from crawling the “images” folder but still wanted to give it access to “img_0001.png” file stored in it, here’s the format you’d use:
For the above example, it would look like this:
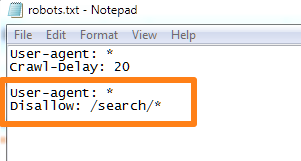
This would stop all pages in the /search/ directory from being indexed.
What if you wanted to stop all pages that matched a specific extension (such as “.php” or “.png”) from getting indexed?
Use this:
User-agent: *
Disallow: /*.extension$
The ($) sign here signifies the end of the URL, i.e. the extension is the last string in the URL.
If you wanted to block all pages with the “.js” extension (for Javascript), here’s what you would use:
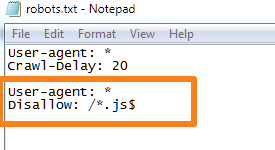
This command is particularly effective if you want to stop bots from crawling scripts.
6. Stop bots from crawling your site too frequently
In the above examples, you might have seen this command:
User-agent: *
Crawl-Delay: 20
This command instructs all bots to wait a minimum of 20 seconds between crawl requests.
The Crawl-Delay command is frequently used on large sites with frequently updated content (such as Twitter). This command tells bots to wait a minimum amount of time between subsequent requests.
This ensures that the server isn’t overwhelmed with too many requests at the same time from different bots.
For example, this is Twitter’s Robots.txt file instructing bots to wait a minimum of 1 second between requests:

You can even control the crawl delay for individual bots. This ensures that too many bots don’t crawl your site at the same time.
For example, you might have a set of commands like this:
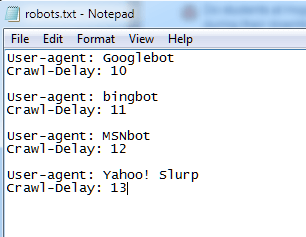
Note: You won’t really need to use this command unless you are running a massive site with thousands of new pages created every minute (like Twitter).
Common mistakes to avoid when using Robots.txt
The Robots.txt file is a powerful tool for controlling bot behaviour on your site.
However, it can also lead to SEO disaster if not used right. It doesn’t help that there are a number of misconceptions about Robots.txt floating around online.
Here are some mistakes you must avoid when using Robots.txt:
Mistake #1 – Using Robots.txt to prevent content from being indexed
If you “Disallow” a folder in the Robots.txt file, legitimate bots won’t crawl it.
But, this still means two things:
- Bots WILL crawl the contents of the folder linked from external sources. Say, if another site links to a file within your blocked folder, bots will follow through an index it.
- Rogue bots – spammers, spyware, malware, etc. – will usually ignore Robots.txt instructions and index your content regardless.
This makes Robots.txt a poor tool to prevent content from being indexed.
Here’s what you should use instead: use the ‘meta noindex’ tag.
Add the following tag in pages you don’t want to get indexed:
<meta name=”robots” content=”noindex”>
This is the recommended, SEO-friendly method to stop a page from getting indexed (though it still doesn’t block spammers).
Note: If you use a WordPress plugin such as Yoast SEO, or All in One SEO; you can do this without editing any code. For example, in the Yoast SEO plugin you can add the noindex tag on a per post/page basis like so:
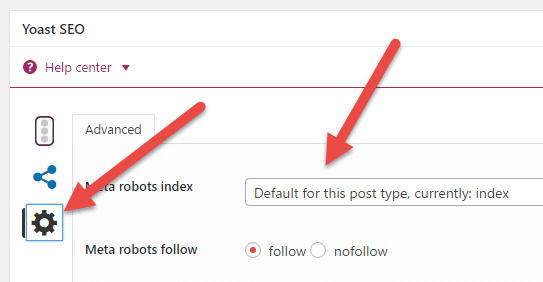
Just open up and post/page and click on the cog inside the Yoast SEO box. Then click the dropdown next to ‘Meta robots index.’
Additionally, Google will stop supporting the use of “noindex” in robots.txt files from September 1st. This article from SearchEngineLand has more information.
Mistake #2 – Using Robots.txt to protect private content
If you have private content – say, PDFs for an email course – blocking the directory via Robots.txt file will help, but it isn’t enough.
Here’s why:
Your content might still get indexed if it is linked from external sources. Plus, rogue bots will still crawl it.
A better method is to keep all private content behind a login. This will ensure that no one – legitimate or rogue bots – will get access to your content.
The downside is that it does mean your visitors have an extra hoop to jump through. But, your content will be more secure.
Mistake #3 – Using Robots.txt to stop duplicate content from getting indexed
Duplicate content is a big no-no when it comes to SEO.
However, using Robots.txt to stop this content from getting indexed is not the solution. Once again, there is no guarantee that search engine spiders won’t find this content through external sources.
Here are 3 other ways to hand duplicate content:
- Delete duplicate content – This will get rid of the content entirely. However, this means that you are leading search engines to 404 pages – not ideal. Because of this, deletion is not recommended.
- Use 301 redirect – A 301 redirect instructs search engines (and visitors) that a page has moved to a new location. Simply add a 301 redirect on duplicate content to take visitors to your original content.
- Add rel=”canonical” tag – This tag is a ‘meta’ version of the 301 redirect. The “rel=canonical” tag tells Google which is the original URL for a specific page. For example this code:
<link href=”http://example.com/original-page.html” rel=”canonical” />
Tells Google that the page – original-page.html – is the “original” version of the duplicate page. If you use WordPress, this tag is easy to add using Yoast SEO or All in One SEO.
If you want visitors to be able to access the duplicate content, use the rel=”canonical” tag. If you don’t want visitors or bots to access the content – use a 301 redirect.
Be careful implementing either because they will impact your SEO.
Over to you
The Robots.txt file is a useful ally in shaping the way search engine spiders and other bots interact with your site. When used right, they can have a positive effect on your rankings and make your site easier to crawl.
Use this guide to understand how Robots.txt works, how it is installed and some common ways you can use it. And avoid any of the mistakes we’ve discussed above.

Follow us on Social Media :)



Post a Comment